2025年中国网络文明大会于6月10日至11日在安徽合肥举行,由中央网信办、中宣部等多个部门联合主办。大会设置了开幕式、主题论坛、14场分论坛及主题活动,围绕网络文明建设的关键议题展开深入探讨,发布研究成果、典型案例,展示先进经验。大会以“汇聚网络正能量 引领时代新风尚”为主题,旨在推动网络空间的文明建设。
在本次大会的“个人信息保护”分论坛中,聚焦数据安全与隐私保护问题,深入研讨个人信息保护法律制度建设、技术保障措施、社会治理机制等内容。该分论坛旨在推动形成全社会尊重、保护个人信息的共识与合力,促进数字社会健康发展。

俞能海教授发表了题为《生成式人工智能时代个人信息保护的挑战与对策》的精彩演讲,深入剖析了生成式AI飞速发展背景下个人信息保护面临的全新严峻挑战,并提出了构建“全民防护、技术管控、责任左移”三位一体的系统性对策。

俞能海教授首先回顾了人工智能技术的发展历程,从达特茅斯会议提出AI概念,到深度学习算法的重大突破,再到AlphaGo战胜人类顶尖棋手,以及近年来ChatGPT、GPT-4、Sora、DeepSeek-R1等生成式AI模型的爆发式增长,展示了人工智能从判决式AI向生成式AI演进的趋势,以及大模型带来的“能力涌现”现象,推动人工智能进入全新形态。

然而,伴随生成式AI的迅猛发展,个人信息保护也面临着前所未有的挑战:
大模型训练阶段的隐私威胁——未经授权的数据采集:大模型训练需要海量数据支撑,但未经用户同意收集和使用其数据进行训练,违反了个人信息保护的相关规定。
大模型应用阶段的隐私信息泄露: AI大模型助手可能存在“实际收集的个人信息超出用户授权范围”或“实际收集个人信息的频率与业务功能没有直接关联”的问题。
大模型能力引发的安全威胁——Deepfake与语音克隆:生成式AI的强大能力也带来了Deepfake(深度伪造)和语音克隆等安全威胁。
信息聚合的隐私泄露:大模型能够聚合海量零散数据,精准描绘用户画像并推断个人信息,这种能力可能被诈骗者利用或用于定向广告,进一步加剧了隐私泄露的风险。
面对上述挑战,俞能海教授提出了三位一体的新型个人信息保护策略:
1、全民防护:提高全民数字素养的基本保证
俞教授强调,个人信息保护是数字时代的基本生存技能。他提出:1.将个人信息保护列为全民素养的“必修课”,引导公众认识数字行为背后的风险责任 ;2.精准触达“银发族”、青少年、大学生等重点人群,推出定制化课程和实践式科普内容;3.利用校园等平台扩大覆盖面,构建“百城、百校、百企”数字素养教育网络,推动校园建立网络安全和个人信息保护专修室,开设科普课堂和实践课程,形成全民知法、懂技、善防的网络行为习惯。
2、技术管控:发展新型个人信息保护技术
深度伪造被动检测技术:中国科大团队研发的基于相位分析与浅层学习的检测方法和基于多注意机制的检测方法能显著提高深伪检测的泛化性和准确率。团队凭借该算法在2020年全球最大的深伪检测挑战赛DFDC中获得全球亚军、国内第一的成果,被评为人工智能安全领域的创新成果。
针对深度伪造的主动防御技术:通过对受保护的人脸添加特定的扰动噪声,使篡改伪造模型失效,从而实现主动防御。
端云协同的大语言模型隐私保护推理框架:利用差分隐私技术对个人信息进行脱敏,同时蒸馏云端模型能力,提升本地模型性能。
3、责任左移:强化制造侧安全责任
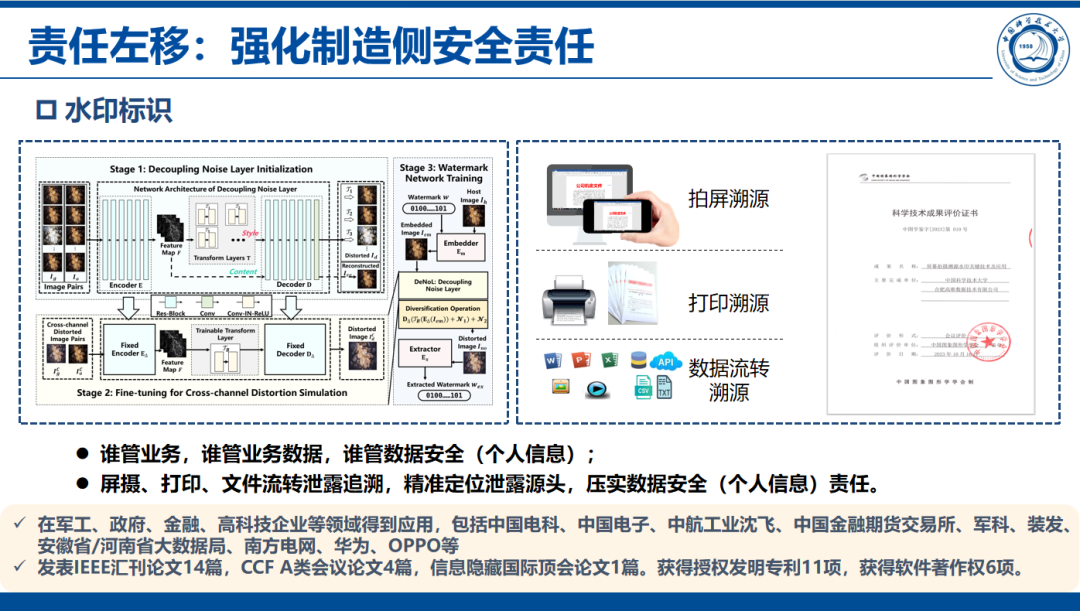
俞教授指出,为了保护个人在应对风险上的弱势地位,产品的制造者和数字应用的开发者应承担更大的安全责任。团队研发的水印标识技术和音色水印技术对强化制造侧安全责任起到支撑作用。
水印标识技术:包括屏摄溯源、打印溯源和文件流转溯源,能够精准定位泄露源头,压实数据安全责任。该技术已在军工、政府、金融、高科技企业等领域得到广泛应用。
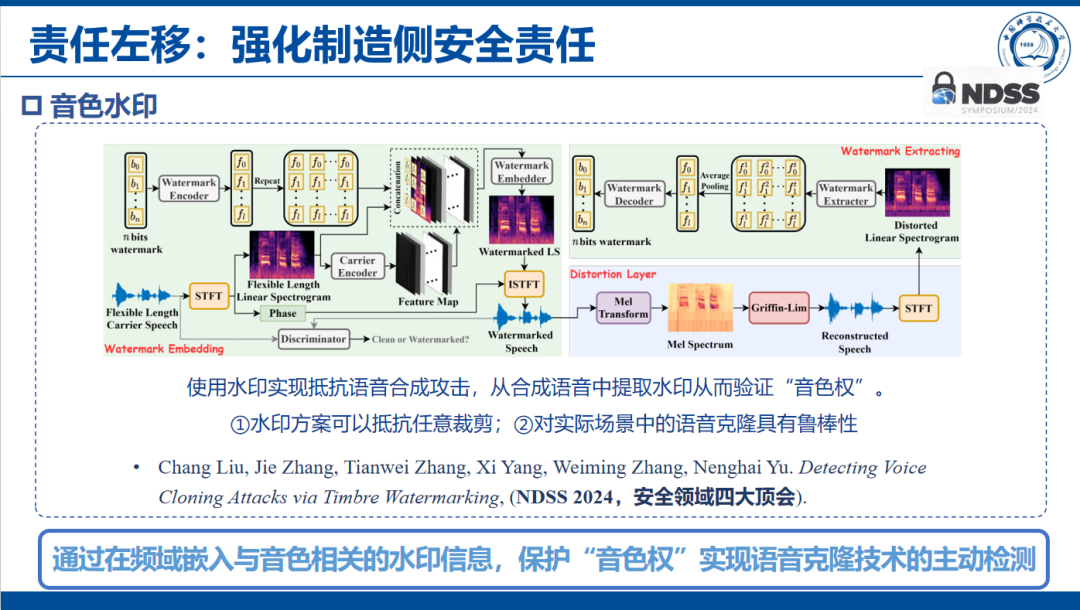
音色水印技术:通过在频域嵌入与音色相关的水印信息,实现抵抗语音合成攻击,并能从合成语音中提取水印,从而验证“音色权”。该方案具有鲁棒性,能够抵抗任意裁剪,并已在国际顶级安全会议上发表论文。
此外,俞教授着重强调,在接到熟人的电话或者视频时,只要涉及转账交易,请各位一定要从另外的渠道重新复核以确定真实性,不要轻易相信对方。
俞教授最后呼吁,应对生成式AI时代的个人信息保护挑战,要打造“全民防护、技术管控、责任左移”的个人信息保护新生态,让技术创新与文明法治同频共振,以中国智慧守护亿万网民的数字家园!
- END -