 转载于 《保密科学技术》杂志 2022年5月刊
转载于 《保密科学技术》杂志 2022年5月刊
作者:
方 涵 张卫明 张志翔 田 辉 王志伦
中国科学技术大学
合肥高维数据技术有限公司
安徽省保密局
【摘要】设计出一种能够抵抗屏摄信道传输的数字水印算法是解决屏摄泄密问题的迫切需求。针对此需求,本文总结了多个可应用于屏摄泄密场景的数字水印技术,从技术发展的角度分别对关键算法进行介绍。同时,通过实验总结了现有屏摄溯源技术的优劣,并对这一研究课题进行了展望。
【关键词】屏摄溯源 数字水印 鲁棒性 不可见性
【中图分类号】 TP393.08 ;TP309
【文献标识码】 A
1、引言
数字水印技术是通过一定的算法在待保护的数字多媒体载体(图像、文档、音频、视频等)中嵌入含有身份标识的秘密信息(数字水印),从而使得数字多媒体载体包含有一种附加信息的功能。而水印信息的嵌入不易被人眼所察觉,也不会对原始载体本身的使用产生影响。最重要的是,它不能够被轻易擦除与破坏。因而,数字水印最常被应用于版权信息认证与失泄密文件追踪。
智能手机性能的提升使信息传输有了新手段,那就是通过手机拍照传输图片来实现。使用手机对计算机屏幕进行拍照这一记录方式能在保证内容质量的前提下很大程度抹除附加水印信号,给水印提取带来新的难题。所以工业界对数字水印提出的新需求就集中体现数字水印需要具有“ 抗屏摄鲁棒性”。近几年来,通过手机偷拍并泄露公司敏感信息从而产生巨大商业损失的案例屡见不鲜,突破“抗屏摄鲁棒性”难题,设计新一代数字水印技术,对于促进新媒体技术的产业应用和商业推广具有重要意义。
近年来,具有屏摄鲁棒性的数字水印算法逐渐被关注,但仍处于起步阶段。因为相比于电子信道失真,如压缩、滤波、加噪等图像处理失真, 屏摄失真更为复杂和随机。电子信道失真能通过数字计算有效地进行模拟,从而可以进行深入分析,针对性地设计出相应的算法来解决问题。而对于屏摄过程,多媒体内容的复制与传输由原始的电子信道传输变为真实的空气信道传输,失真产生于屏幕拍照过程。这种跨媒介传输过程引入的失真极为复杂,包括伽马变换、JPEG压缩、 透视失真等一系列复杂失真,不可简单使用已知图像处理过程进行建模,不易进行定量分析。相对于传统的图像处理失真,屏摄传输对多媒体内容的改变更大,这也意味着对水印鲁棒性的要求更高,传统的针对电子信道的鲁棒水印算法已经不能有效解决这种场景下的问题。如何有针对性地通过数字算法的设计,达到屏摄鲁棒性的需求,成为现阶段数字水印领域热点问题。

2、屏摄水印技术研究进展
2.1 基于传统特征的水印算法
目前大多数屏摄鲁棒水印算法都是基于传统特征设计的。在屏摄鲁棒水印之前,学术论文更关注的是打印拍照的鲁棒性。Nakamura 等[ 1 ] 在2004年首先提出了一种满足打印拍照鲁棒性的水印算法,通过设计正交的模板图案表达“ 0 / 1 ”比 特,再以叠加的方式嵌入水印图像中,保证水印信号在打印拍照前后的一致性 。之后 ,Primila 等发表了多篇文章 [ 2 - 4 ] 关注打印拍照的鲁棒性,但原理与参考文献[ 1 ] 相似,都是通过设计不同的模板表达水印消息,实现屏摄鲁棒的效果, 但其针对性地设计了预处理和后处理算法,使水印能更好地被嵌入和提取。Fang 等 [ 5 ] 在2018年以 “ 屏摄鲁棒水印 ”为题提出了一种屏摄鲁棒溯源水印算法,这也是学术界第一次将屏摄失真作为重要失真进行分析。在参考文献[ 5 ] 中,作者将屏摄过程中的主要失真分成了镜头失真、光照失真和摩尔纹失真3个方面,并通过对失真的分析,提出了一种基于尺度不变特征变换(SIFT)特征点结合离散余弦变换(DCT )的算 法,有效保证了数字水印在屏摄失真中的鲁棒性 。除了SIFT特征, Chen等人 [ 6 ] 提出了一种基于加速稳健特征(SURF)和离散傅里叶变换 (DFT ) 的屏摄鲁棒水印算法,通过对局部方形特征区域的傅里叶系数的调制,实现水印的嵌入。基于此算法,Chen等人[ 7 ] 又提出了一种结合图像加密的屏摄鲁棒水印算法,有效地将加密过程和水印过程融合,保证了有权限用户的行为可追溯性。L i 等人[ 8 ] 提出了一种基于“ 超级点” ( Super Point )的特征定位算法,保证嵌入的特征点能在屏摄水印前后都被有效定位,再通过对傅里叶系数的调制实现水印的嵌入与提取。基于传统特征的水印方案大多与图片特征有关,包括特征定位和水印嵌入两个步骤 。而Gugel mann 等人[ 9 ] 提出了一种在屏幕中添加水印的方案,通过使用明暗不同的图形表达“ 0 / 1 ” 比特,并叠加在屏幕上实现水印的嵌入过程。
2.2 基于深度学习特征的水印算法
随着深度学习技术在图像处理各个环节中的应用,深度学习的特征提取能力已逐步被挖掘。近年来,也有多种基于深度学习特征的水印方法被提出。Zhu等人 [ 1 0 ] 首先提出了 “ 编码器—噪声层—解码器” 的深度学习水印框架,通过在噪声层中添加失真,实现特定的鲁棒性。但这样的方案不能保证不可导失真的鲁棒性,所以为解决屏摄过程这一不可导失真的问题,出现了两种典型思路。第一种是通过可导过程模拟屏摄失真,加入到噪声层中进行训练。Jia等 人 [ 1 1 ] 提出了一种模拟屏摄全过程的方案,包括几何变换、噪声、滤波、颜色变换等图像处理操作,通过训练的方式实现了对屏摄失真的鲁棒性。另一种思路是将屏摄过程当作黑盒子,使用神经网络模拟屏摄过程,再将模拟的网络当作噪声层加入到深度学习框架中进行训练。Wengrowsk i 等人[ 1 2 ] 提出了一种 “ 屏摄转换网络” (CDTF),通过构建屏摄前后数据对能有效模拟屏摄过程并将此网络加入到深度学习框架中进行训练。这一算法对于深度学习框架而言也更为典型。
3、屏摄水印典型算法
本节分别介绍基于传统特征的水印算法[ 5 ]和基于深度学习特征的水印算法[ 12 ]细节。
3.1 基于SIFT特征和DCT系数的屏摄鲁棒水印算法
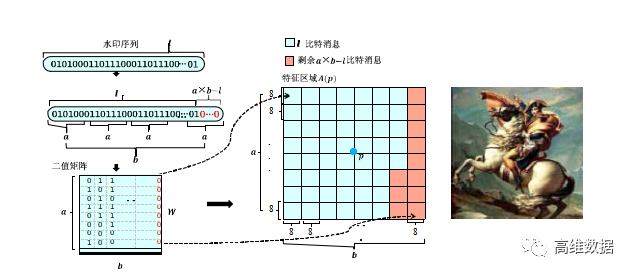
图1 基于SIFT特征和DCT系数的屏摄鲁棒水印算法嵌入过程示意图
图 1 展示了基于SIFT特征和DCT系数的屏摄鲁棒水印算法[ 5 ] 的嵌入过程,主要步骤为:对版权信息进行处理,生成待嵌入的水印序列;利用SIFT特征点定位算法在载体图像中定位及筛选出若干特征点,对特征点周围的待嵌入区域通过频域调制的方式将水印序列进行嵌入,生成含水印的图像。下面对这一过程进行详细介绍。
( 1 )对版权信息进行线性分组纠错(BCH)编码,并将其重构成 a × b 的二值矩阵W,得到待嵌入的水印序列,其中的 a 与 b 均为整数。
( 2 ) 对载体图像进行预处理:若载体图像为彩色图像,则将RGB空间的图像转化为YCbCr空间的图像,并将Y通道图像作为待嵌入图像 I ,若载体图像为灰度图,则直接将载体图像作为待嵌入图像I 。
( 3 ) 特征点定位:对于一张待嵌入图像I ,通过下采样得到采样后的图像 I o; 对图像 I o 进行不同平滑程度的高斯滤波得到一系列滤波后图像。进行高斯滤波时,高斯滤波核的方差决定了滤波平滑的程度。之后,对不同平滑程度的滤波图像进行差分操作,得到一系列差分图像, 记为高斯差分空间。
D( p )= D( x , y , σ )= L( x , y , kσ )- L( x , y , σ )
记 p = ( x , y , σ ) 为高斯差分空间中的点;对每个高斯差分空间中的点,均与以其自身为中心的3 × 3 × 3的立方体中除其自身之外的其余26个点进行对比,如果 D ( p ) 为其中的最大值或最小值,则认为 p是特征点。
( 4 )特征点筛选:每个水印比特需要使用 8 × 8 的像素去嵌入,待嵌入的水印序列为 a × b 的二值矩阵,将需要 ( a × b ) × ( 8 × 8 ) 大小的以特征点为中心的像素块。由于嵌入区域不能重叠,需要对上个步骤得到的 n 个特征点进行筛选,筛选出特征点强度尽可能大 且不重叠的k 个区域作为候选嵌入区域,最终筛选出 k 个满足要求的特征点 。
( 5 ) 对每一个特征点周围的待嵌入区域 B,将其分成 a × b 个 8 × 8 的块,针对每个块对其进行离散余弦变换得到大小为 8 × 8 的离散余弦矩阵 D,取出中频系 数C1 = D( 4 , 5 ) 和 C2 = D( 5 , 4 ),在嵌入水印时做如下处理:为待嵌入的水印比特。为了保证在经过手机压缩过程后C1,C2仍然满足设定的大小关系,增加冗余量d使其中d = | C 1 - C 2 | 。根据待嵌入的水印比特 w、JPEG压缩表中对应的量化系数q1 和 q2 、嵌入强度 r 、中频系数C1 和C2以及冗余量d计算嵌入量 。
在每个比特嵌入完成后,对块进行离散余弦反变换, 完成嵌入过程,得到图像 I E M ;若载体图像为灰度图像,则图像 I E M 直接作为嵌入完成图像;若载体图像为彩色图像,则将图像 I E M 替换原有的Y 通道图像并重构R G B 图像作为嵌入完成图像。
对于水印提取阶段而言,当含水印的图像被非法拍摄并流传时,我们需要对屏摄图像进行透视畸变校正,再通过裁剪方式获取所需的图像,之后,通过特征点定位算法定位出嵌入位置并使用交叉验证的提取方法将水印序列进行提取,进而复原出版权信息。
( 1 ) 对于屏摄图像 I '',我们需要进行透视畸变的校正,并裁剪出我们需要提取的图像。
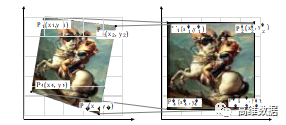
图2 透视校正示意图
图2展示了透视畸变校正的过程,确定含水印的图像的4个顶点在屏摄图像 I ' ' 中的位置,4个顶点记为 P i ( x i , y i ) ,同时设置校正后预期的这4个点的位置为 P i ' ( x i ' , y i ' ) ,其中 i ∈ { 1 , 2 , 3 , 4 } ;根据这8个顶点位置求解出对应的8个变量a0 , b0 , a1 , b1 , c1 , a2 , b2 , c2 , 这8个变量决定了从失真图像( 即屏摄图像 I'' )到校正图像的映射关系,计算出这 8 个变量后能形成一个从失真图到校正图之间像素一一对应的映射;之后通过校正后点的位置(即, P i ' ( x i ' , y i ' ) )裁剪出需要提取的图像。
( 2 ) 对于裁剪得到的图像,如果为灰度图像,则利用SIFT特征点定位算法进行特征点定位及筛选;如果为彩色图像转化为YCbCr空间的图像,并提取Y通道 图像,再利用SIFT特征点定位算法进行特征点定位及筛选;特征点定位及筛选的方式与水印嵌入阶段的方式相同,此时筛选出2k个特征点。
( 3 )对每一个特征点进行一个3 × 3 邻域的遍历,即对每一个特征点,需要对 9 个以该特征点及其邻域点为中心的大小为( a × b ) × (8×8) 的区域进行提取操作 ;对于一张图像,共提取2 × k × 9个区域。
对于每一个待提取的区域,将其分解成 a × b 个大小为 8 × 8 的像素块;针对每个块对其进行离散余弦变换得到大小为 8 × 8 的离散余弦矩阵 D ,取出中频系数 C1 = D ( 4 , 5 ) 和 C2 = D ( 5 , 4 ) ,并根据中频系数计算嵌入的水印比特w 。
对于一张图像,一共提取出了 2 × k × 9个水印,记W q ( W q = [ w q1 , w q2 … w q9 ] ) 为由特征点p q提取出的水印组;从两个不同的组W q 与 W r 中分别提取两个水印 w qα 和 w rβ 作为一个水印对来进行比较, 然后记录所有差别小于设定值th的水印对 w f ,如下述公式所示:得到 1 个水印对,每个水印对包括 2 个水印,故总共得到21个水印。
对于任一相同位置,如果21个水印中超过l个水印在该位置的水印值为1,则该位置水印值为1 ,否则认为该位置水印值为 0 。
( 4 ) 当提取出水印编码后,将其重构成一维的序列,并通过BCH码解码复原出版权信息。
3.2 基于CDTF的深度学习屏摄鲁棒水印算法
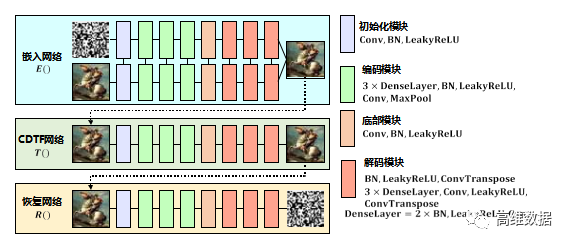
图3 基于CDTF的深度学习屏摄鲁棒水印框架
图3展示的基于CDTF的深度学习屏摄鲁棒水印 [ 1 2 ] 的 框架包括嵌入网络E、CDTF网络T和恢复网络R。3个网络串联,组成完整的可端到端训练的网络。这3个网络主要的构成如下所述。
( 1 ) 嵌入网络E:嵌入网络E的输入是载体图片和原始消息,嵌入网络由两支相同结构的子网络组成,2个网络共同作用,组合输出含水印图像。
( 2 ) CDTF网络T:CDTF网络的作用是模拟屏摄过程,通过预先采集的屏摄数据集先训练一个屏摄模拟网络,再将此网络当作噪声层加入到整个深度学习框架中进行训练。CDTF网络的输入是含水印图像,输出是经过模拟屏摄过程后的失真图像。
( 3 ) 恢复网络R:恢复网络的作用是从失真图像中恢复出原始嵌入的消息,恢复网络的输入是失真图像,输出是原始水印信息。
整个网络是端到端训练的,训练过程如下。
( 1 ) 屏摄数据集的获取:在训练嵌入网络和恢复网络之前,我们需要预先训练CDTF网络,这一网络代表了屏摄过程中的失真。所以第一步,我们首先需要通过真实拍摄过程获得一个足够数量的输入和输出屏摄数据对,用于训练CDTF 网络,数据对中屏摄后的图像需要进行透视校正。
( 2 ) CDTF网络的训练:在得到屏摄数据集后,就可以进行CDTF网络的训练了。CDTF网络的输入为原始图像,输出为屏摄后图像,通过设置相应的损失函数来实现网络的训练。
( 3 ) 嵌入网络和恢复网络的训练:在CDTF 网络训练结束后,需要对嵌入网络和恢复网络进行训练。这两个网络是端到端训练的,在训练过程中,需要固定住预训练的CDTF网络,只更新嵌入网络和恢复网络的参数,整个大网络设置相应的损失函数进行约束。
4、实验结果与分析
本节首先介绍上述2种算法的实现细节,包括数据集和屏摄设备等。同时展现算法嵌入水印后图像的视觉质量,以及在不同角度、不同距离下的屏摄实验结果。
4.1 实现细节
算法测试使用的数据集为USC - SIPI数据集,每一张图片都被缩放至1 2 8 × 1 2 8 × 3 像素的大小,嵌入的水印容量为3 0比特。在训练深度学习网络时,使用的数据集为MS-COCO 数据集的 10000 张随机图像。屏摄使用的手机为“ HuaweiP30 Pro ” ,显示器为“ LenovoLEN9053 ” 。评价视觉质量的指标为峰值信噪比PSNR 和结构相似度SSIM ,评价鲁棒性的指标为比特错误率。
4.2 视觉质量

图4 不同算法的视觉质量
我们首先用 4 张图片展示利用 2 种算法生成的图像的主观视觉质量,如图4所示。可以看出,两种算法都保证了较高的视觉质量,但在某一些细节方面仍然存在视觉失真。
PSNR 和SSIM 的对比如表1所示,可以看出,参考文献[ 5 ] 相较于参考文献 [ 12 ] 有着一定的视觉质量优势,可能的原因是参考文献[5 ] 是选择图像中的一部分图像块进行嵌入,但参考文献 [12] 却是在原图的所有部分进行嵌入,所以产生的视觉质量有一定的劣势。
4.3 屏摄实验结果
表1 不同方法的视觉质量对比

本节将分别从不同的屏摄距离、不同的屏摄角度进行屏摄实验来验证算法的屏摄鲁棒性。屏摄距离选择的是 20 - 60 cm ,角度选择的是左40 ° 到右40 °,上40 ° 到下40 ° ,以10 °为一个间隔。实验结果展示在表2、表3和表4中。
表2 不同距离下的屏摄鲁棒性
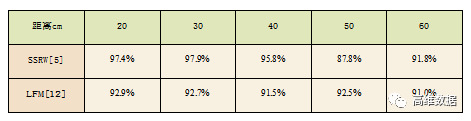
从表2中可以看出,对于不同的距离,两种方法都有着一定的提取准确率,但总体而言,参考文献 [ 5 ] 的方案保证了较高的提取准确率,在20 — 40cm 的情况下,准确率都大于95%,而在50 — 60cm的情况下,提取准确率在90%左右。对于参考文献 [ 12 ] 的方案,准确率在所有距离下都稳定在91% 左右 。
表3 不同水平角度下的屏摄鲁棒性

表4 不同垂直角度下的屏摄鲁棒性

从表3和表4可以看出,两种算法在大多数屏摄角度下都保持着高于90%的准确率,但是随着屏摄角度的变大,准确率也有所下滑,这是因为屏摄角度变大产生的失真更为严重,从而进一步影响提取的准确性。
5、结语
本文主要从“ 屏摄鲁棒性” 这一现实需求牵引的性质的角度出发,总结了现有数字水印算法在屏摄鲁棒性的部分工作。由于屏摄过程的复杂性,设计屏摄鲁棒的数字水印算法并非易事,能有效保证多角度屏摄下的鲁棒水印更是难点问题。现阶段的工作大多停留在以图片为载体进行方案的设计,通过人工特征结合变换域系数的方法或通过深度学习训练的方法查找可用特征并进行实验。但在视觉质量和鲁棒性两方面仍存在一定的改进空间。
这里, 本文对后续水印算法可能的发展方向做出简要阐述。
( 1 )基于图像载体的屏摄鲁棒水印方案有一个前提,那就是屏摄图像中需要包含完整的电子图像,当只拍摄了图像的一部分时,算法就不能很好地保证鲁棒性了,这一缺陷在基于图像的算法中几乎都存在。原因在于提取时需要对图像进行透视畸变校正,而校正的前提就是使用图像的四个顶点,所以仅拍摄了部分图像时,就无法定位到4个顶点用于校正了。但在真实场景下,也有可能出现只拍摄一部分图像的情况,那么如何针对部分屏摄图像的场景,解决部分图像的校正和提取问题,是一个重要的研究方向。
( 2 ) 深度学习的特征提取能力会因为神经网络结构和训练集的丰富程度变化而变化,如何更好地根据屏摄失真的特点有针对性地设计神经网络结构,是优化提取端的重要任务。如何根据场景定制噪声层也是实现神经网络数字水印的重要一环。M
【参考文献】
[1]Takao Nakamura, Atsushi Katayama, Masashi Yamamuro, Noboru Sonehara. Fast Watermark Detection Scheme for Camera-equipped Cellularphone[C]. In Proceedings of the 3rd International Conference on Mobile and Ubiquitous multimedia.2004: 101~108.
[2]Anu Pramila, Anja Keskinarkaus, TapioSeppänen. Reading Watermarks from Printed Binary Images witha Camera Phone[C]. in Proc. of IWDW, Guildford, UK, 2009:227~240.
[3]Anu Pramila, Anja Keskinarkaus, TapioSeppänen. Toward an Interactive Poster Using Digital Watermarking and a Mobile Phone Camera[J].Signal, Image and Video Processing, 2012,6:211~222.
[4]Anu Pramila, Anja Keskinarkaus, Valtteri Takala, TapioSeppänen. Extracting Watermarks from Printouts Captured with Wide Angles Using Computational Photography[J].Multimedia Tools and Applications 2017,76(15):16063~16084.
[5]Han Fang, Weiming Zhang, Hang Zhou, Hao Cui, Nenghai Yu. ScreenShooting Resilient Watermarking[J]. IEEE Transactions on Information Forensicsand Security,201814,(06): 1403~1418.
[6]Wentong Chen, Na Ren, Changqing Zhu, Qifei Zhou, TapioSeppänen, Anja Keskinarkaus. Screen- Cam Robust Image Watermarking with Feature-based Synchronization[J]. Applied Sciences,2020, 10(21): 7494.
[7]WentongChen,NaRen,ChangqingZhu,TapioSeppänen,AnjaKeskinarkaus,QifeiZhou.JointImage EncryptionandScreencamRobustTwoWatermarking Scheme[J]. Sensors, 2021, 21(3):701.
[8]Li Li, Rui Bai, Shanqing Zhang, Chin-Chen Chang, MengtaoShi. Screen-Shooting Resilient Watermarking Scheme via Learned Invariant Keypoints and QT[J]. Sensors, 2021, 2119:6554.
[9]David Gugelmann, David Sommer, Vincent Lenders, Markus Happe, Laurent Vanbever. Screen Watermarking for Data Theft Investigation and Attribution[C].In201810th International Conference on Cyber Conflict (CyCon). IEEE, 2018:391~408.
[10]Jiren Zhu, Russell Kaplan, Justin Johnson, Li Fei- Fei. Hidden: Hiding Data with Deep Networks[C]. In Proceedings of the European Conference on ComputerVision (ECCV),2018:657~672.
[11]Jun Jia ,Zhongpai Gao, Kang Chen, Menghan Hu, Xiongkuo Min, GuangtaoZhai, XiaokangYang. RIHOOP: Robust Invisible Hyperlinks in Offline and Online Photographs[J].in IEEE Transactions on Cybernetics, doi: 10.1109/TCYB.2020.3037208.
[12]Eric Wengrowski and Kristin Dana. Light Field Messaging With Deep Photographic Steganography[J].ComputerVisionFoundation/ IEEE,2019: 1515~1524.
- END -